Now that we've explored various evaluation techniques and methodologies, and also some concrete evaluations in different categories of capability, propensity and control. The next thing to understand is how to implement these effectively at scale. The objective of this section is to outline some best practices for building a robust evaluation infrastructure - from designing evaluation protocols and quality assurance processes, to scaling automation and integrating with the broader AI Safety ecosystem. We'll see how components like evaluation design, model-written evaluations, and meta-evaluation methods work together to make AIs safer.
Affordances #
Affordances are resources and opportunities we give the AI system. They include things like access to the internet, ability to run code, available context length, or specialized tools like calculators (Sharkey et al., 2024). Just like how a calculator makes certain math problems trivial while others remain hard, different affordances can dramatically change what an AI system can accomplish during evaluation.
Different evaluation conditions modify the affordances available to the model during testing. This means that even when measuring the same property, we can increase or decrease the amount of affordance a system has, and this tells us different things about a model's capabilities:
- Minimal affordance: You can think of minimal affordance conditions as sort of the worst case for the model. We deliberately restrict the resources and opportunities available - like limiting context length, removing tool access, or restricting API calls. When evaluating coding ability, this might mean testing the model with no access to documentation or ability to run code. This helps establish a baseline of core capabilities independent of external tools.
- Typical affordance: Under typical affordance conditions, we aim to replicate the normal operating environment - providing standard tools and typical context. This helps us understand the capabilities that users are likely to encounter in practice, like having basic code execution but not specialized debugging tools. Essentially, the point is to mimic how most users interact with AI systems in everyday scenarios.
- Maximal affordance: Under maximal affordance conditions, we provide the model with all potentially relevant tools, context, and resources. For that same coding evaluation, we might provide access to documentation, debugging tools, and execution environments. This helps us understand the full extent of what the model can accomplish when given appropriate resources.
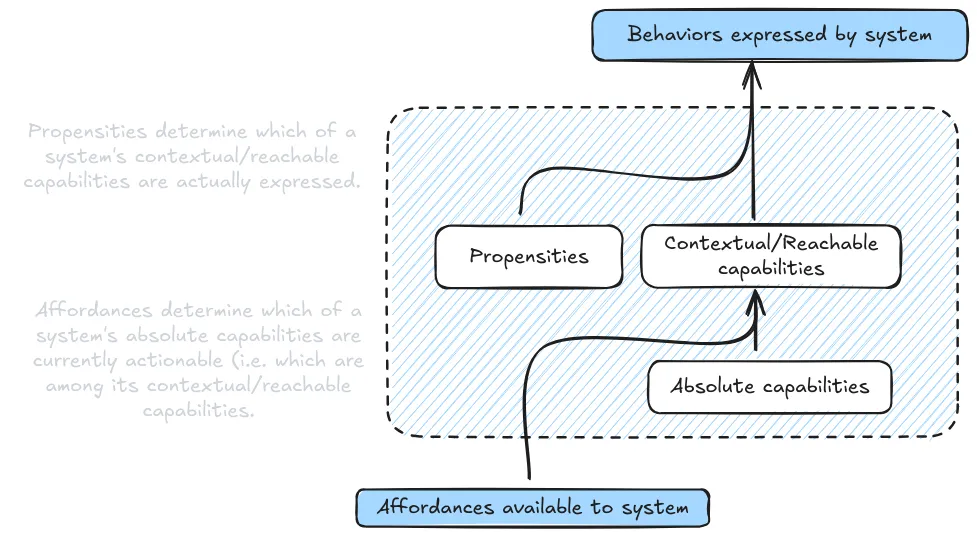
Understanding the relationship between affordances and capabilities helps us design more comprehensive evaluation protocols. For instance, when evaluating a model's coding capabilities, testing under minimal affordances might reveal concerning behaviors that are masked when the model has access to better tools. Maybe the model suggests unsafe coding practices when it can't verify its solutions through execution. Similarly, testing under maximal affordances might reveal emergent capabilities that aren't visible in more restricted environments - like how GPT-4's ability to play Minecraft only became apparent when given appropriate scaffolding and tools (Wang et al., 2023).
Quality assurance in evaluation design. Given how significantly affordances affect model behavior, we need systematic approaches to ensure our evaluations remain reliable and meaningful. This means carefully documenting what affordances were available during testing, verifying that affordance restrictions are properly enforced, and validating that our results are reproducible under similar conditions. For instance, when the U.S. and UK AI Safety Institutes evaluated Claude 3.5 Sonnet, they explicitly noted that their findings were preliminary due to testing under limited affordances and time constraints (US & UK AISI, 2024).
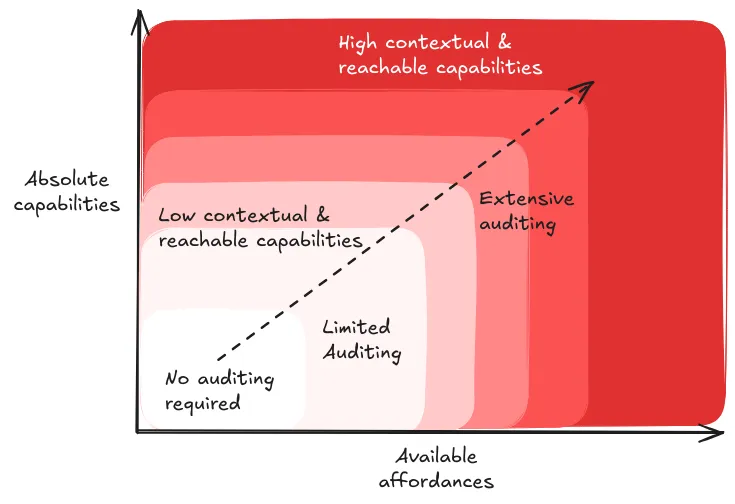
Moving beyond individual evaluations. While understanding affordances is crucial for designing individual evaluations, we also need to consider how different evaluation conditions work together as part of a larger system. A comprehensive evaluation protocol might start with minimal affordance testing to establish baseline capabilities, then progressively add affordances to understand how the model's behavior changes. This layered approach helps us build a more complete picture of model behavior while maintaining rigorous control over testing conditions.
Scaling and Automation #
In previous sections, we explored various evaluation techniques and conditions, but implementing these systematically faces a major challenge: scale. When OpenAI or Anthropic release a new model, dozens of independent researchers and organizations need to verify its capabilities and safety properties. Doing this manually for every evaluation under different affordance conditions would be prohibitively expensive and time-consuming. We need systems that can automatically run comprehensive evaluation suites while maintaining the careful control over conditions we discussed earlier.
Automating evaluation through model written evaluations (MWEs). As we scale up evaluations, we need to make strategic decisions about resource allocation. Do we run many quick evaluations under different conditions, or fewer evaluations with more thorough testing? One approach is using automated tools to do broad initial testing, then dedicating more resources to deep investigation of concerning behaviors. This tiered approach helps balance the need for comprehensive coverage with limited resources. One approach is using AI models themselves to help generate and run evaluations. Even current language models can write high-quality evaluation questions when properly prompted (Perez et al., 2022). This approach might help address the scaling challenge by reducing the human effort needed to create new evaluations.

We still face significant challenges in automating evaluations. First, we need to maintain quality as we scale - automated systems must be able to reliably enforce affordance conditions and detect potential evaluation failures. Second, generated evaluations need to be validated to ensure they're actually testing what we intend. As Apollo Research found, model-written evaluations sometimes had systematic blindspots or biases that needed to be corrected through careful protocol design (Dev & Hobbhahn, 2024).
Integration and Audits #
How do evaluations fit into the broader safety ecosystem? When we talk about evaluations being used in practice, we're really talking about two distinct but complementary processes. First, there are the specific evaluation techniques we've discussed in previous sections - the tools we use to measure particular capabilities, propensities, or safety properties. Second, there's the broader process of auditing that uses these evaluations alongside other analysis methods to make comprehensive safety assessments.
Why do we need multiple layers of evaluations? The UK AI Safety Institute's approach demonstrates why integration requires multiple complementary layers. Their evaluation framework incorporates regular security audits, ongoing monitoring systems, clear response protocols, and external oversight - creating what they call a "defense in depth" approach (UK AISI, 2024). This layered strategy helps catch potential risks that might slip through any single evaluation method.
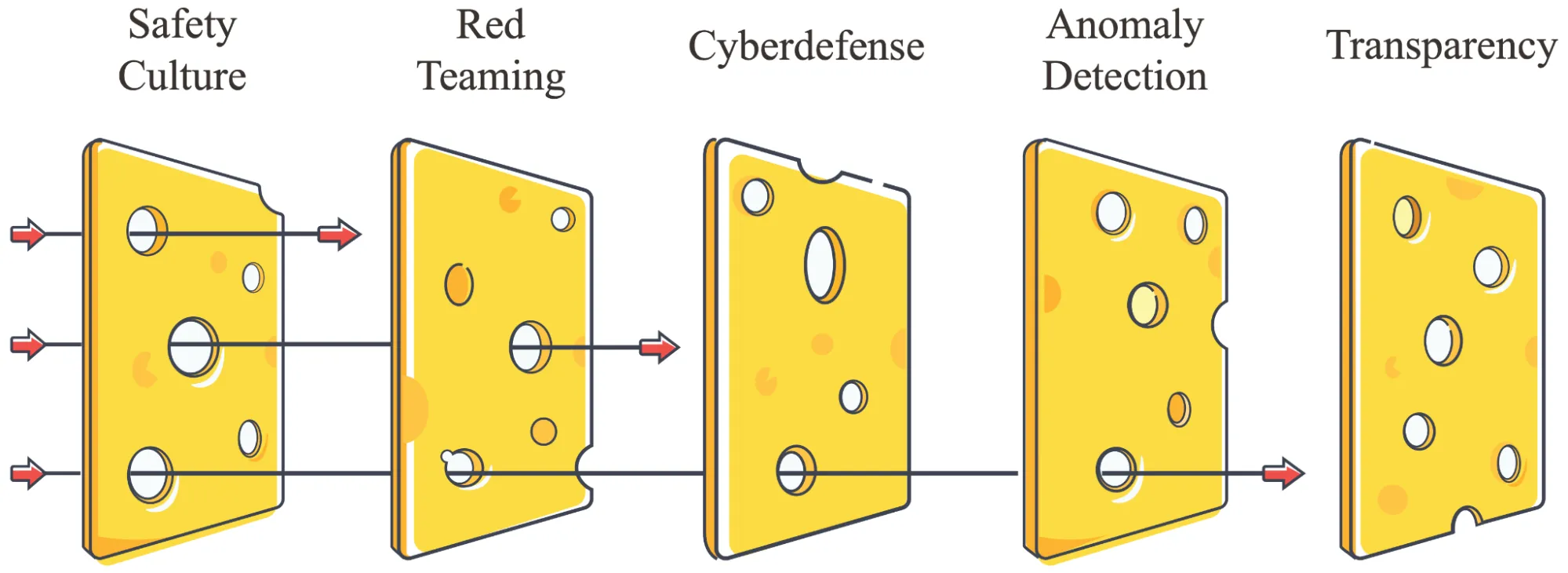
What makes auditing different from evaluation? While evaluations are specific measurement tools, auditing is a systematic process of safety verification. An audit might employ multiple evaluations, but also considers broader factors like organizational processes, documentation, and safety frameworks. For example, when auditing a model for deployment readiness, we don't just run capability evaluations - we also examine training procedures, security measures, and incident response plans (Sharkey et al., 2024).
What types of audits do we need? Different aspects of AI development require different types of audits:
- Training design audits: These verify safety considerations throughout the development process. Before training begins, auditors examine factors like compute usage plans, training data content, and experiment design decisions. During training, they monitor for concerning capabilities or behaviors. For instance, training audits might look for indicators that scaling up model size might lead to dangerous capabilities (Anthropic, 2024).
- Security audits: These assess whether safety measures remain effective under adversarial conditions. This includes technical security (like model isolation and access controls) and organizational security (like insider threat prevention).
- Deployment audits: These examine specific deployment scenarios. They consider questions like: Who will have access? What affordances will be available? What safeguards are needed? These audits help determine whether deployment plans adequately address potential risks. For example, deployment audits might assess both direct risks from model capabilities and potential emergent risks from real-world usage patterns of those capabilities (Apollo Research, 2024).
- Governance audits: These look at organizational safety infrastructure. They verify that companies have appropriate processes, documentation requirements, and response protocols. This includes reviewing incident response plans, oversight mechanisms, and transparency practices (Shevlane et al., 2023).
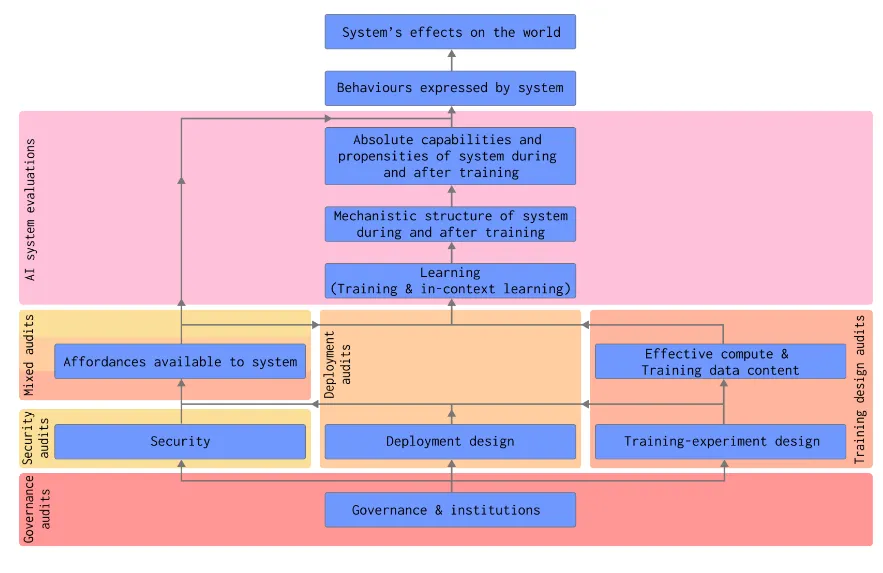
Evaluations support the auditing process because each type of audit uses different combinations of evaluations to gather evidence. For example, a deployment audit might use capability evaluations to establish upper bounds on risky behaviors, propensity evaluations to understand default tendencies, and control evaluations to verify safety measures. The audit process then synthesizes these evaluation results with other evidence to make safety assessments.
Internal auditing is a great first step but we also need independent external audits. Third party audits provide additional assurance by bringing fresh perspectives and diminishing the probability for potential conflicts of interest. Organizations like METR and Apollo Research demonstrate how independent auditors can combine multiple evaluation techniques to provide comprehensive safety assessments. However, this ecosystem is still developing, and we need more capacity for independent evaluation of frontier AI systems (Shevlane et al., 2023). We talk more about bottlenecks to third party auditing in the limitations section.
After deployment, we need ongoing monitoring and periodic re-auditing. We need this for several reasons - First, we need to catch unanticipated behaviors that emerge from real-world usage. Second, we need to evaluate any model updates or changes in deployment conditions. Third, we need to verify that safety measures remain effective. This creates a feedback loop where deployment observations inform future evaluation design and audit procedures (Shevlane et al., 2023; Phuong et al., 2024; UK AISI, 2024; Sharkey et al., 2024).
For evaluations and audits to have real impact, they must connect directly to decision-making processes. Both evaluations and audits need clear, predefined thresholds that trigger specific actions. For example, concerning results from capability evaluations during training might trigger automatic pauses in model scaling. Failed security audits should require immediate implementation of additional controls. Poor deployment audit results should modify or halt deployment plans (Sharkey et al., 2024).
These action triggers need to be integrated into broader governance frameworks. As we discussed in the chapter on governance, many organizations are developing Responsible Scaling Policies (RSPs) that use evaluation results as "gates" for development decisions. However, without strong governance frameworks and enforcement mechanisms, there's a risk that evaluations and audits become mere checkbox exercises - what some researchers call "safety washing". We'll explore these limitations and potential failure modes in more detail in the next section.
Was this section useful?
Thank you for your feedback
Your input helps improve the Atlas.